In the last years an increasing number of modern websites out there are what is called JavaScript rendered websites. A JavaScript rendered website loads the initial page from the server and then uses JavaScript to fetch and render additional content as needed. This approach allows for a more responsive and interactive user experience, as the website can update specific parts of the page without requiring a complete refresh.
This said, JavaScript rendered websites can be challenging to scrape because the content is dynamically generated and updated by JavaScript, making it harder for traditional web scraping techniques to extract data.
For instance ImportXML, the native scraping Google Sheets function works with basic websites only but not with JS websites.
Fortunately, ImportFromWeb does provide a solution to easily scrape data from JavaScript rendered websites, overcoming the difficulties posed by dynamic content and allowing for seamless data extraction.
Using ImportFromWeb to scrape JavaScript rendered website
The IMPORTFROMWEB() formula can be supercharged with powerful options. One of them, the js_rendered option, enables to extract data from the JS rendered webpages.
When using the js_rendering option, our crawlers will wait for the page to load completely before starting the scraping, thus the user can retrieve all the page data without any issues.
Using the js_rendering option you will be able to retrieve content from almost any website out there. In some cases, you also need to add the time_to_wait option in order to give some time for the page content to load (render). This is how the function with these options included will look like:
=IMPORTFROMWEB(B1,B2,"js_rendering,time_to_wait:10")
How to know when to use the js_rendering option
Some technical skills are required to check if a website is JS rendered or not. So instead of making this effort to check this, every time when our function that should return a data that is visible on the page returns #ALL_SELECTORS_RETURN_NULL, #PAGE_IS_EMPTY or a similar error, the first thing we recommend you to try is the js_rendering together with the time_to_wait options.
In case you would like to know for sure whether the website is JS rendered or not there are plenty of articles and tools our there. You can add the Toggle JavaScript extension to Chrome or go through some of through this or this article in order to learn more about it.
Example on how to scrape a JavaScript rendered website with ImportFromWeb
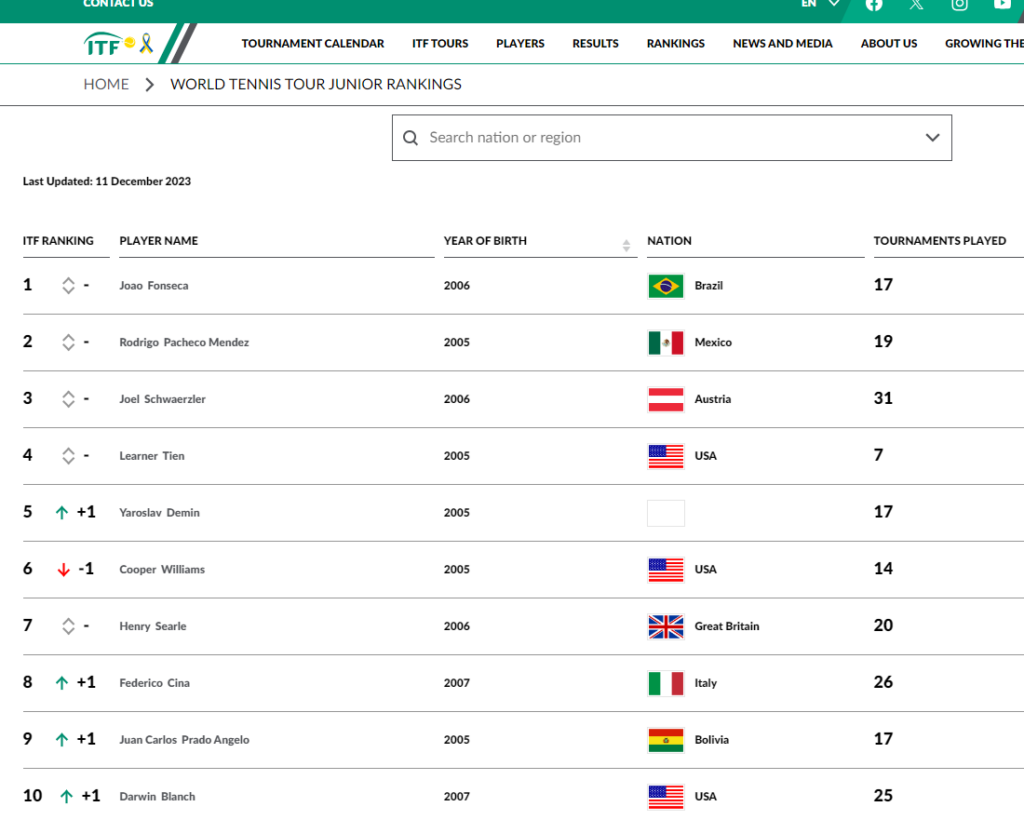
Let’s now see this option in action. In this example we want to scrape the top 10 Tennis Junior Ranking Players from the International Tennis Federation website.
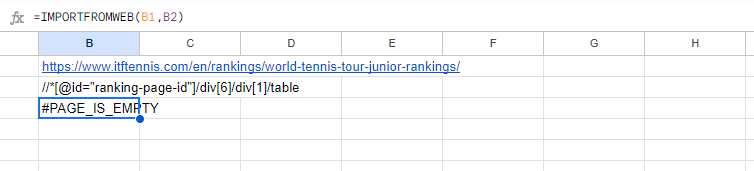
If we write the function in the regular way, we would get a “#PAGE_IS_EMPTY” in our sheet as you can see on the following screenshot:
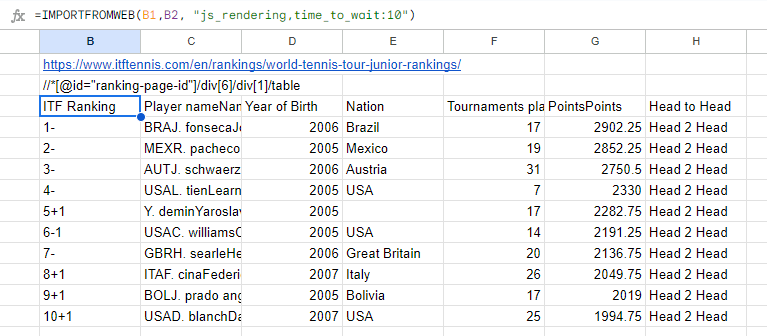
This is because this website is JS rendered and we need to add the “js_rendering” option together with “time_to_wait” in order to get this data. We are now going to add these options and as you can see on the following image the data is properly retrieved now:
Time to wait values
In these example we are using the “time_to_wait” set to 10 seconds as in our experience it is sufficient time to load the content on most of the websites. However some websites are faster and this number can be decreased to 5 seconds for faster data retrieval. Some websites are also slower so we you can test with 20 seconds in case the 10 seconds wait is not sufficient to retrieve the content.